
Knots (links) are embeddings of the circle (some finite number of circles) into the 3-sphere, modulo ambient isotopy. Knot theory is thus the study of the essentially different ways we can embed a circle into a 3-sphere—a kind of deformation theory for such maps, if you will. From this perspective, it is perhaps not too surprising that knot theory has developed connections to many areas of pure and applied mathematics.
For example, knot complements and Dehn surgery are important sources of examples for 3-manifolds. Knot complements are intimately related to knots themselves, by the Gordon-Luecke theorem; Dehn surgery not only has the virtue of being explicitly computable, it is also a fairly generic source of 3-manifolds, by the Lickorish-Wallace theorem.
Or, for example, knot theory shows up in physics in various ways. Indeed, knot theory and physics tangled from fairly early on: most prominently, Lord Kelvin’s theory of “vortex atoms” posited that atoms can be modeled as knots of aether. While this turned out to be wrong from a physical standpoint, it did inspire Tait to start classifying knots and spur the mathematical development of knot theory; and it may yet find a spiritual successor in the “anyons” of topological quantum computing.
Yet another early connection can be seen in the linking number, one of the first knot (or link) invariants, which Gauss came up in his study of a question from electrodynamics: how much work is done on a magnetic pole moving along a closed loop in the presence of a loop of current? Using the Ampere and Biot-Savart law, he found the answer could be described in terms of how many times one of these loops winds around the other, or in other words the linking number of the two loops (see e.g. pp. 2-4 here.)
Knot invariants
More generally, knot (or link) invariants are mathematical objects—numbers, polynomials, homology groups, whatever have you—attached to knots (or links—I’ll stop writing this, but you should imagine inserted after each instance of “knot” below.) Equivalent (i.e. ambient-isotopic) knots should be assigned the same value—hence the name “invariant”—although certain pairs of non-equivalent knots may also be assigned equal values.
These are useful, primarily, for distinguishing knots—for providing a verifiable certificate that two knots are indeed inequivalent, as it were.
It is straightforward enough, in principle, to prove that two knots are equivalent: one simply exhibits an ambient isotopy taking one to the other. Indeed, this ambient isotopy can always be described within an explicitly-described standard combinatorial model—using a class of standard local “moves”, the Reidemeister moves, on knot diagrams, i.e. projections of the knot to a plane, decorated with additional information about which strand crosses “over” the other at each double point.
(Completely tangential aside: knot diagrams can be an endless source of combinatorial fun—see e.g. this REU paper on games on shadows of knots.)
It is rather harder to prove that two knots are inequivalent this way: failure to exhibit a suitable sequence of Reidemeister moves doesn’t prove that an ambient isotopy can’t exist—perhaps with more ingenuity one could in fact find the requisite Reidemeister moves? Hence the utility of knot invariants: if we can show that two knots take on different values for a certain knot invariant, that definitively shows that they are inequivalent.
Some examples of knot invariants include the crossing number—which can be defined as the minimum number of crossings (double points) which any knot diagram of a given knot must have—, the unknotting number—which can be defined as the least number of times one needs to pass a knot through itself (or, equivalently, the least number of crossings that need to be switched) to get to an unknot—, and the Seifert genus—the minimal genus of any connected oriented surface whose boundary is the knot.
These invariants are intuitive and natural measures of the “complexity” of a knot, but are notoriously hard to compute and study. For instance, it is conjectured, but still not known, that the crossing number is additive under taking connect-sums, and it took a surprising amount of work (an Inventiones paper!) to show that composite knots have unknotting number at least 2. In some sense, an understanding of these invariants can be seen as a primary aim, rather than a tool, of knot theory.
More computable, but in some ways less intuitive and more mysterious, are invariants of a more algebraic nature: things such as the signature or Arf invariant coming from naturally-associated quadratic forms, or various knot polynomials which package this and other knot data into their coefficients. The theory behind and extending from these knot polynomials, in particular has driven much of modern knot theory, and we touch on some of these developments below.
The turn to combinatorics (and algebra)
Starting with Conway’s work on the Alexander polynomial in the 1960s, it has been realized that many of these polynomials can be defined and computed combinatorially, using skein relations; building on this, and introducing language and ideas from statistical mechanics, Kauffman formulated state-sum models for computing the Alexander and Jones polynomials in the 1980s.
This was not the first time physics had popped up here, either: models from statistical mechanics motivated the von Neumann algebras and braid representations which were originally used to define the Jones polynomial. This was in many ways a pivotal development in the theory: to borrow The Unapologetic Mathematician’s words:
Jones was studying a certain kind of algebra when he realized that the defining relations for these algebras were very much like those of the braid groups. In fact, he was quickly able to use this similarity to assign a Laurent polynomial … to every knot diagram that didn’t change when two diagrams differed by a Reidemeister move. That is, it was a new invariant of knots.
The Jones polynomial came out of nowhere, from the perspective of the day’s knot theorists. And it set the whole field on its ear. From my perspective looking back, there’s a huge schism in knot theory between those who primarily study the geometry and the “classical topology” of the situation and those who primarily study the algebra, combinatorics, and the rising field of “quantum topology”. To be sure there are bridges between the two … But the upshot was that the Jones polynomial showed a whole new way of looking at knots and invariants.
Extending the skein relation approach to build invariants on a larger class of knots with singular points leads us to the theory of the much more powerful, and possibly fundamental finite-type (Vassiliev) invariants, which has subsequently been studied using such tools as chord diagrams and the Kontsevich integral.
Knot homology theories
Another, related direction in which knot polynomials have taken off is towards homological algebra, in a development sometimes described as “categorification”. Categorifying a knot polynomial involves building a homology whose Euler characteristic—in an appropriate sense, involving some sort of alternating sum of data from the homology groups—recovers the knot polynomial.
The homology groups of a topological space contain all the information carried by the Euler characteristic, and then some; in some sense, they are the more fundamental invariant, of which the Euler characteristic is just a “decategorified shadow”. Similarly, a knot homology theory should be, in principle at least, more powerful and fundamental than the polynomial it categorifies .
The two main (flavors of) knot homology are Khovanov homology and knot Floer homology. Khovanov homology, developed in the late 1990s by Mikhail Khovanov, is related to ideas in representation theory, and categorifies the Jones polynomial. Knot Floer homology, developed by Ozsváth and Szabó and independently by Rasmussen, both in the early 2000s, is based off Heegaard Floer theory, “a symplectic geometric replacement for gauge theory”, and categorifies the Alexander polynomial.
There are connections between these homology theories and Lie algebras, symplectic geometry, 3- and 4-dimensional topology, physics, and so on, about which I am entirely ignorant at the moment …
Quantum things (also, strings)
Quantum mechanics has already made a brief cameo above. Indeed, as hinted but not spelt out above, many pieces of mathematics which appear in quantum mechanics and related physical theories can be leveraged to create knot invariants—e.g. the Jones polynomial can be recovered from Chern-Simons theory, and the Kontsevich integral is inspired by perturbative Chern-Simons theory.
The connections run much deeper—it appears that knots and braids provide, or are an integral part of, some of the most compelling mathematical models for quantum phenomena, and even make aspects of their appearance felt in string theory. Now, as before, knot theory remains intertwined with physics, although now mediated through the elaborate structure of representation theory in its various guises.
 action on the moduli space
action on the moduli space  of translation surfaces (= moduli space of Abelian differentials, under the identification we made
of translation surfaces (= moduli space of Abelian differentials, under the identification we made  and any
and any 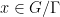 , the closure of the orbit
, the closure of the orbit  is an orbit of a closed algebraic subgroup of G.
is an orbit of a closed algebraic subgroup of G. of complex structures.
of complex structures.  consisting of those quadratic differentials which can be represented as global squares of holomorphic 1-forms.
consisting of those quadratic differentials which can be represented as global squares of holomorphic 1-forms. to
to and
and 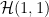 are each connected and consist entirely of
are each connected and consist entirely of  , which points in P can (or cannot) be reached by billiard trajectories through x? A point y which can be reached from x is said to be illuminated from x.
, which points in P can (or cannot) be reached by billiard trajectories through x? A point y which can be reached from x is said to be illuminated from x.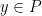 which are not illuminated from x.
which are not illuminated from x. , reflecting off rectangular obstacles (“trees”) placed along a
, reflecting off rectangular obstacles (“trees”) placed along a  lattice in a billiards-like fashion. One can also describe it, precisely, as billiards in the plane with these rectangles removed.
lattice in a billiards-like fashion. One can also describe it, precisely, as billiards in the plane with these rectangles removed.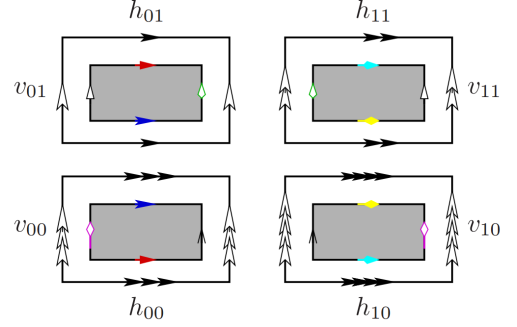
 .
. to be (locally) our dz. Since
to be (locally) our dz. Since 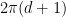 . Where
. Where  , and a specified direction, consider a fundamental polygon
, and a specified direction, consider a fundamental polygon  embedded (anywhere, but with orientation dictated by the specified direction) in the complex plane. The fundamental polygon inherits a natural complex coordinate z. This does not descend to the translation surface, but since the identification maps are all of the form
embedded (anywhere, but with orientation dictated by the specified direction) in the complex plane. The fundamental polygon inherits a natural complex coordinate z. This does not descend to the translation surface, but since the identification maps are all of the form  where
where 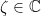 is a constant (for each identification map), the holomorphic 1-form dz does, and we obtain a holomorphic 1-form
is a constant (for each identification map), the holomorphic 1-form dz does, and we obtain a holomorphic 1-form 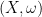 , where X denotes a Riemann surface structure, and
, where X denotes a Riemann surface structure, and  and
and  are considered equivalent if there is a conformal map from
are considered equivalent if there is a conformal map from  to
to 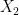 which takes (specified) zeroes of
which takes (specified) zeroes of  to (specified) zeroes of
to (specified) zeroes of  .
. , consisting of forms with zeroes of degree
, consisting of forms with zeroes of degree  with
with  . This last identity follows from the formula for the sum of degrees of zeroes of a holomorphic 1-form on a Riemann surface of genus g, and can be interpreted as a Gauss-Bonnet formula for the singular flat metric.
. This last identity follows from the formula for the sum of degrees of zeroes of a holomorphic 1-form on a Riemann surface of genus g, and can be interpreted as a Gauss-Bonnet formula for the singular flat metric. action on this moduli space (or, really, on each stratum) which is most easily described back in the framework of flat geometry: given any pair
action on this moduli space (or, really, on each stratum) which is most easily described back in the framework of flat geometry: given any pair  , build the corresponding flat polygon (with distinguished vertical direction.) Elements of
, build the corresponding flat polygon (with distinguished vertical direction.) Elements of 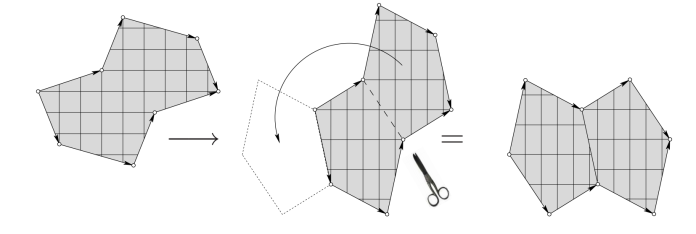
 where
where 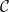 is a specified configuration of saddle connections or closed geodesics.
is a specified configuration of saddle connections or closed geodesics. on [N] which sends j to the square
on [N] which sends j to the square  which we get to by starting at j and moving left, up, right, and down in turn. For the generic square j,
which we get to by starting at j and moving left, up, right, and down in turn. For the generic square j,  .
. ; an affine plane in
; an affine plane in  intersects this in some union of closed and unbounded intervals. Question: how does an unbounded component propagate in
intersects this in some union of closed and unbounded intervals. Question: how does an unbounded component propagate in  ), we are looking at plane sections of the quotient surface
), we are looking at plane sections of the quotient surface 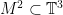 . Our original intersection can be viewed as level curves of a linear function
. Our original intersection can be viewed as level curves of a linear function  restricted to
restricted to  , but this does not push down to the quotient; instead, we consider the codimension-one foliation of
, but this does not push down to the quotient; instead, we consider the codimension-one foliation of 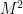 defined by the closed 1-form
defined by the closed 1-form 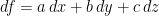 .
.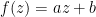 where
where  (and is in particular real) and
(and is in particular real) and 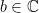 .
.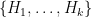 if G acts (geometrically) on some hyperbolic metric space X s.t. the quotient
if G acts (geometrically) on some hyperbolic metric space X s.t. the quotient  is quasi-isometric to the union of k copies of
is quasi-isometric to the union of k copies of 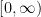 joined at 0.
joined at 0. corresponds to a cusp, or some region where hyperbolicity breaks down; under a quasi-isometry which sends the compact core of the manifold to a point, each cusp (each of these “bad regions”) should be quasi-isometric to a ray going out to infinity.
corresponds to a cusp, or some region where hyperbolicity breaks down; under a quasi-isometry which sends the compact core of the manifold to a point, each cusp (each of these “bad regions”) should be quasi-isometric to a ray going out to infinity.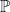 if it acts on a hyperbolic metric space X, and the action is co-compact away from some equivariant collection of horoballs (in X) centered at the parabolic points of G.
if it acts on a hyperbolic metric space X, and the action is co-compact away from some equivariant collection of horoballs (in X) centered at the parabolic points of G. , but we omit them here in the interest of brevity; see e.g. Hruska.)
, but we omit them here in the interest of brevity; see e.g. Hruska.)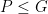 is parabolic if it is infinite and contains no loxodromic element. A parabolic subgroup P has a unique fixed point
is parabolic if it is infinite and contains no loxodromic element. A parabolic subgroup P has a unique fixed point 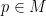 , which we call a parabolic point; stabilizers of parabolic points are maximal parabolic subgroups. A parabolic point p is bounded if its stabilizer acts cocompactly on
, which we call a parabolic point; stabilizers of parabolic points are maximal parabolic subgroups. A parabolic point p is bounded if its stabilizer acts cocompactly on 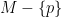 .
.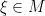 is a conical limit point if it exhibits a sort of generalized north-south dynamics (again, for the exact formulation, see e.g. Hruska), and a convergence group action is geometrically finite if every point of M is ether a conical limit point or a bounded parabolic point.
is a conical limit point if it exhibits a sort of generalized north-south dynamics (again, for the exact formulation, see e.g. Hruska), and a convergence group action is geometrically finite if every point of M is ether a conical limit point or a bounded parabolic point.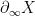 for some hyperbolic metric space X on which G acts on properly; even more specifically, we may take that X to be the Cayley graph of G with combinatorial horoballs attached over the peripheral cosets (= cosets of the peripheral subgroups.)
for some hyperbolic metric space X on which G acts on properly; even more specifically, we may take that X to be the Cayley graph of G with combinatorial horoballs attached over the peripheral cosets (= cosets of the peripheral subgroups.) is the graph with vertex set
is the graph with vertex set  and the “obvious” horizontal and vertical edges. The vertical edges are all assigned length 1, whereas the horizontal edges at level
and the “obvious” horizontal and vertical edges. The vertical edges are all assigned length 1, whereas the horizontal edges at level 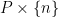 are assigned length
are assigned length 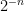 . This has the effect of making the most efficient path between two points distance n apart in the same peripheral coset a horizontal path at level
. This has the effect of making the most efficient path between two points distance n apart in the same peripheral coset a horizontal path at level  , bookended by vertical ascent to / descent from that level.
, bookended by vertical ascent to / descent from that level. and
and  whenever
whenever  , and all of these edges have length 1. There are also (horizontal and vertical) 2-cells attached, although these are ignored when regarding the combinatorial horoball as a metric space.
, and all of these edges have length 1. There are also (horizontal and vertical) 2-cells attached, although these are ignored when regarding the combinatorial horoball as a metric space.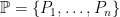 iff the electrified Cayley graph, formed by taking a Cayley graph by adding to the Cayley graph a vertex (“cone point”) for each left coset
iff the electrified Cayley graph, formed by taking a Cayley graph by adding to the Cayley graph a vertex (“cone point”) for each left coset  and edges of length 1/2 from this new vertex to each element of
and edges of length 1/2 from this new vertex to each element of 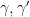 which start and end at (essentially) the same point,
which start and end at (essentially) the same point,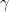 and
and 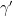 penetrate a coset gP, then the entering vertices of
penetrate a coset gP, then the entering vertices of  apart.
apart. , and a relative Dehn function is a Dehn function for the relative presentation, with conjugating elements for the relators taken from K (for a less terse / cryptic definition, again see e.g. Hruska, or
, and a relative Dehn function is a Dehn function for the relative presentation, with conjugating elements for the relators taken from K (for a less terse / cryptic definition, again see e.g. Hruska, or 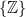 )—the electrified Cayley graph here is hyperbolic, but not fine, i.e. the BCP is not satisfied. Indeed, in some sense, there are “too many bad regions” which are “not sufficiently separated”, and so the theory of relative hyperbolicity does not help here.
)—the electrified Cayley graph here is hyperbolic, but not fine, i.e. the BCP is not satisfied. Indeed, in some sense, there are “too many bad regions” which are “not sufficiently separated”, and so the theory of relative hyperbolicity does not help here.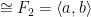 ) is hyperbolic, but also hyperbolic relative to the cusp group
) is hyperbolic, but also hyperbolic relative to the cusp group ![\langle [a,b] \rangle](https://s0.wp.com/latex.php?latex=%5Clangle+%5Ba%2Cb%5D+%5Crangle&bg=ffffff&fg=000000&s=0&c=20201002) .
. to each of the pieces P: given any point x in our space,
to each of the pieces P: given any point x in our space,  is the unique point in
is the unique point in  which every geodesic from x to P must go through. With these projections defined, we can say even more. In a tree-graded space, if
which every geodesic from x to P must go through. With these projections defined, we can say even more. In a tree-graded space, if  , then any geodesic between two points must go through P. The appropriately coarsified version of this is true for relatively hyperbolic groups:
, then any geodesic between two points must go through P. The appropriately coarsified version of this is true for relatively hyperbolic groups: , and then goes to y from there. The geodesic may track several peripheral subsets, in turn, this way, going between them in an essentially unique (hyperbolic) way; additional structural results, again analogous to results for tree-graded spaces, tell us more about the order in which these peripheral subsets appear, and so on.
, and then goes to y from there. The geodesic may track several peripheral subsets, in turn, this way, going between them in an essentially unique (hyperbolic) way; additional structural results, again analogous to results for tree-graded spaces, tell us more about the order in which these peripheral subsets appear, and so on. . If we fix the genus, area, and singularity data for our surface, the translation surface can only have large diameter if it contains a (long) cylinder. In particular, if our translation surface had area greater than some universal constant D, we have our cylinder, and hence a closed orbit.
. If we fix the genus, area, and singularity data for our surface, the translation surface can only have large diameter if it contains a (long) cylinder. In particular, if our translation surface had area greater than some universal constant D, we have our cylinder, and hence a closed orbit. is said to be ergodic (w.r.t. the given measure
is said to be ergodic (w.r.t. the given measure  ) if any T-invariant subset of X has either zero or full measure w.r.t.
) if any T-invariant subset of X has either zero or full measure w.r.t.  of
of  by taking the vertex set to be the set of group elements, and adding an edge
by taking the vertex set to be the set of group elements, and adding an edge  iff
iff  for some
for some  .
.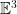 , hyperbolic 3-space
, hyperbolic 3-space 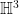 , and the 3-sphere
, and the 3-sphere 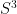 ;
; and
and  ; and
; and , Nil, and Sol.
, Nil, and Sol. such that
such that  (possibly up to index 2), and a subgroup
(possibly up to index 2), and a subgroup  such that
such that  (again, possibly up to index 2), and
(again, possibly up to index 2), and  which preserves
which preserves 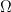 .
. as the projectivization of a 4-dimensional vector space
as the projectivization of a 4-dimensional vector space  , i.e.
, i.e. 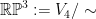 where we identify vectors in
where we identify vectors in  is in fact the full group of collineations in this case, since the Galois group
is in fact the full group of collineations in this case, since the Galois group 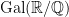 is trivial.
is trivial. on
on 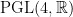 .)
.)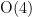 , and we may take
, and we may take  with signature (-+++), let
with signature (-+++), let  ; then the isotropy group is isomorphic to (the appropriate finite-index subgroup of)
; then the isotropy group is isomorphic to (the appropriate finite-index subgroup of) 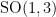 .
. (
( being the rotation matrix
being the rotation matrix 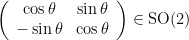 ) is what Molnár calls the screw collineation group.
) is what Molnár calls the screw collineation group. acts freely on the base space
acts freely on the base space  .
.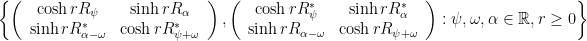
 and
and  is the twisted rotation matrix
is the twisted rotation matrix 
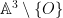 , where O is a fixed origin, and also equip the resulting punctured affine space with a line bundle—or really, a product structure—, with base space homeomorphic to the 2-sphere, and fibres given by open half-rays pointing outwards from O.
, where O is a fixed origin, and also equip the resulting punctured affine space with a line bundle—or really, a product structure—, with base space homeomorphic to the 2-sphere, and fibres given by open half-rays pointing outwards from O. -subgroup of isometries of the unit 2-sphere, dilatations in the
-subgroup of isometries of the unit 2-sphere, dilatations in the  direction, and inversions in our distinguished family of 2-spheres.
direction, and inversions in our distinguished family of 2-spheres. where again O is a fixed origin in the affine chart. Analogous to the previous case, equip
where again O is a fixed origin in the affine chart. Analogous to the previous case, equip  -subgroup of isometries of the hyperbolic 2-space, dilatations in the
-subgroup of isometries of the hyperbolic 2-space, dilatations in the 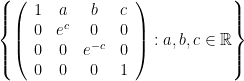 .
. of constant height c, and the fibres the “vertical” lines
of constant height c, and the fibres the “vertical” lines 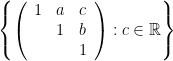 .
.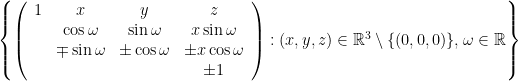 .
. is space of all tuples of n distinct points in X, i.e. we may think of it as the open manifold
is space of all tuples of n distinct points in X, i.e. we may think of it as the open manifold 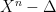 , where here $\latex \Delta$ denotes the extended diagonal consisting of all n-tuples where the values of at least two coordinates coincide.
, where here $\latex \Delta$ denotes the extended diagonal consisting of all n-tuples where the values of at least two coordinates coincide.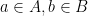 , or in other words
, or in other words  , and fix
, and fix 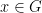 (to be made public.) Alice and Bob choose secret keys a and b from A and publish
(to be made public.) Alice and Bob choose secret keys a and b from A and publish  as public keys.
as public keys.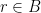 and sends
and sends  , where H is some hash function and
, where H is some hash function and  denotes XOR.
denotes XOR. and then
and then  .
. as exponentiation, the security of this protocol would depend on the difficulty of finding discrete logarithms.
as exponentiation, the security of this protocol would depend on the difficulty of finding discrete logarithms. , find
, find 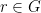 s.t.
s.t.  .)
.) . Here we describe them, for the fun of it, and because a potential closer analysis of their security suggests potentially interesting problems (or perhaps exercises—I don’t know enough / haven’t spent enough time to be able to judge) regarding automorphisms of free groups.
. Here we describe them, for the fun of it, and because a potential closer analysis of their security suggests potentially interesting problems (or perhaps exercises—I don’t know enough / haven’t spent enough time to be able to judge) regarding automorphisms of free groups. , a key-space
, a key-space  consisting of some large number N (say,
consisting of some large number N (say, 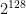 ) of automorphisms of
) of automorphisms of  with maximal period length.
with maximal period length. with rank equal to the alphabet size, a (minimal
with rank equal to the alphabet size, a (minimal  , Alice generates an equally-long string of congruences
, Alice generates an equally-long string of congruences  using h, and sends the ciphertext
using h, and sends the ciphertext  as an unreduced word in
as an unreduced word in  for all
for all 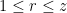 and
and  , and uses this to chunk the ciphertext into words corresponding to individual letters, which are then decrypted using the corresponding
, and uses this to chunk the ciphertext into words corresponding to individual letters, which are then decrypted using the corresponding 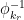 .
. given h and
given h and 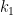 ) for cryptographic security, although the protocol itself (a one-time pad) is not terribly sophisticated.
) for cryptographic security, although the protocol itself (a one-time pad) is not terribly sophisticated.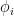 are randomly chosen. Moldenhauer proposes a system which uses binary strings, of varying lengths (details unspecified here) and maps these to Whitehead automorphisms in some systematically random way.
are randomly chosen. Moldenhauer proposes a system which uses binary strings, of varying lengths (details unspecified here) and maps these to Whitehead automorphisms in some systematically random way. in the free group, and an automorphism
in the free group, and an automorphism  of infinite order.
of infinite order. , and publish as their public keys
, and publish as their public keys  .
. and send this to Bob as the ciphertext.
and send this to Bob as the ciphertext. .
. , have Bob not immediately decrypt, but instead compute
, have Bob not immediately decrypt, but instead compute  and send this back to Alice, and then have Alice compute
and send this back to Alice, and then have Alice compute  . Now Bob decrypts the message by computing
. Now Bob decrypts the message by computing 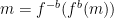 .
. to Bob; Bob computes
to Bob; Bob computes  and verifies that this matches with Alice’s public key
and verifies that this matches with Alice’s public key  .
. and
and  ; i.e. the difficulty of the (analogue of the) discrete logarithm in generic infinite cyclic subgroups of the free group.
; i.e. the difficulty of the (analogue of the) discrete logarithm in generic infinite cyclic subgroups of the free group. ?
? 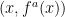 , since
, since  , and both
, and both 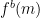 are exchanged in the protocol. How many of these would Eve need to collect before she can try to effectively reconstruct what
are exchanged in the protocol. How many of these would Eve need to collect before she can try to effectively reconstruct what  is? How much will the cancellation / free reduction created by concatenating signatures (or other material) to the end of messages alleviate this?
is? How much will the cancellation / free reduction created by concatenating signatures (or other material) to the end of messages alleviate this? (i.e. f is smooth with non-degenerate critical points), we can consider the topology of the sublevelsets, and pair up critical points which cause connected component to be added or removed. A persistence diagram is a diagrammatic representation of this pairing (figure from
(i.e. f is smooth with non-degenerate critical points), we can consider the topology of the sublevelsets, and pair up critical points which cause connected component to be added or removed. A persistence diagram is a diagrammatic representation of this pairing (figure from 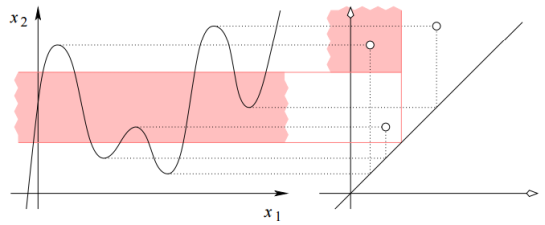
 on a n-manifold
on a n-manifold  , we obtain n persistence diagrams, one in each degree
, we obtain n persistence diagrams, one in each degree  of (nonvanishing) homology.
of (nonvanishing) homology. .
.![k[t]](https://s0.wp.com/latex.php?latex=k%5Bt%5D&bg=ffffff&fg=000000&s=0&c=20201002) -module structure;
-module structure;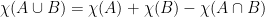 . One can formalize this and build a theory of integration “with respect to Euler characteristic” (
. One can formalize this and build a theory of integration “with respect to Euler characteristic” (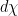 ) by defining
) by defining  for characteristic functions of (sufficiently nice) sets, and then extending linearly and using limits.
for characteristic functions of (sufficiently nice) sets, and then extending linearly and using limits. of a set A the measure of A, we associate to
of a set A the measure of A, we associate to  , and we “scan” T by slicing along hyperplanes and recording the Euler characteristic of the slices of T—which, in the case of a compact set of the plane, is simply the number of connected components minus the number of holes (which equals the number of bounded connected components of the complement—a baby case of Alexander duality.) This yields a function
, and we “scan” T by slicing along hyperplanes and recording the Euler characteristic of the slices of T—which, in the case of a compact set of the plane, is simply the number of connected components minus the number of holes (which equals the number of bounded connected components of the complement—a baby case of Alexander duality.) This yields a function  (the domain here is the affine Grassmannian of all planes in
(the domain here is the affine Grassmannian of all planes in 
 ) as follows: encode the information from the “scan” in the relation
) as follows: encode the information from the “scan” in the relation  by
by  if
if 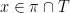 . We may verify h is related to
. We may verify h is related to 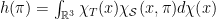 (a Radon transform, but with
(a Radon transform, but with  denote the fiber
denote the fiber  ; then
; then  for all
for all 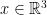 (each point in T appears on a compact set of affine planes) and
(each point in T appears on a compact set of affine planes) and  for all
for all  (given
(given  , the affine planes which see both of them are exactly the ones which contain the line containing both of them—and there is a circle’s—or technically a
, the affine planes which see both of them are exactly the ones which contain the line containing both of them—and there is a circle’s—or technically a  ‘s—worth of such planes.)
‘s—worth of such planes.)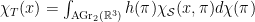 .
. records the total number of targets it senses in its range; the sensors can also communicate with nearby sensors (those with overlapping ranges) to exchange and compare target counts, but that is the limit of their capabilities. Given this, and that the sensor ranges overlap in undescribed ways, how should we go about recovering an accurate global count?
records the total number of targets it senses in its range; the sensors can also communicate with nearby sensors (those with overlapping ranges) to exchange and compare target counts, but that is the limit of their capabilities. Given this, and that the sensor ranges overlap in undescribed ways, how should we go about recovering an accurate global count?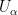 be the subset of all
be the subset of all  s.t. the sensor at x senses
s.t. the sensor at x senses  is the counting function which simply returns the number of targets counted by the sensor at x. In a toy case where
is the counting function which simply returns the number of targets counted by the sensor at x. In a toy case where 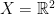 —so that we did not have to worry about boundary effects—and all the target supports were perfect circles of radius R, we would have
—so that we did not have to worry about boundary effects—and all the target supports were perfect circles of radius R, we would have  , or
, or 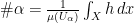 , where here both dx and
, where here both dx and 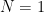 ), then we can apply exactly the same logic, but using Euler integration instead of Lebesgue integration, to show that the number of
), then we can apply exactly the same logic, but using Euler integration instead of Lebesgue integration, to show that the number of 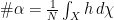 .
.